Containers allow you to package applications and all their dependencies in a common format and ship it to your runtime environment. But what are the fundamental technologies containers are build on? And why do we need a Linux Kernel for that?
The following post is a written summary of a lecture I gave as an introduction to Kubernetes. The code is based on the excellent talk and code of Liz Rice some years ago.
What is a container?
If you think about a container you might think about a tiny operating system that runs your application. But a container is no virtual machine or micro virtual machine. A container is an isolated process that runs on a Linux system. It is isolated in the sense that it has its own file system, network, and process space, depending on the configuration. The question is why does this work only on Linux (Kernel)? And yes I know there are other container technologies like FreeBSD jails, but let's focus on the main driver for adoption, the Linux Kernel.
Containers provide us the following benefits:
- Stable runtime environment for applications
- Pack all dependencies together with the application
- Isolation from other applications. With proper configuration we don't run into the noisy neighbor problem.1
If we start an Ubuntu container in interactive mode (docker run -it ubuntu /bin/bash) and run ps in it, we should only see two processes. The first one will be the shell we started the container with and the second one will be our ps command.
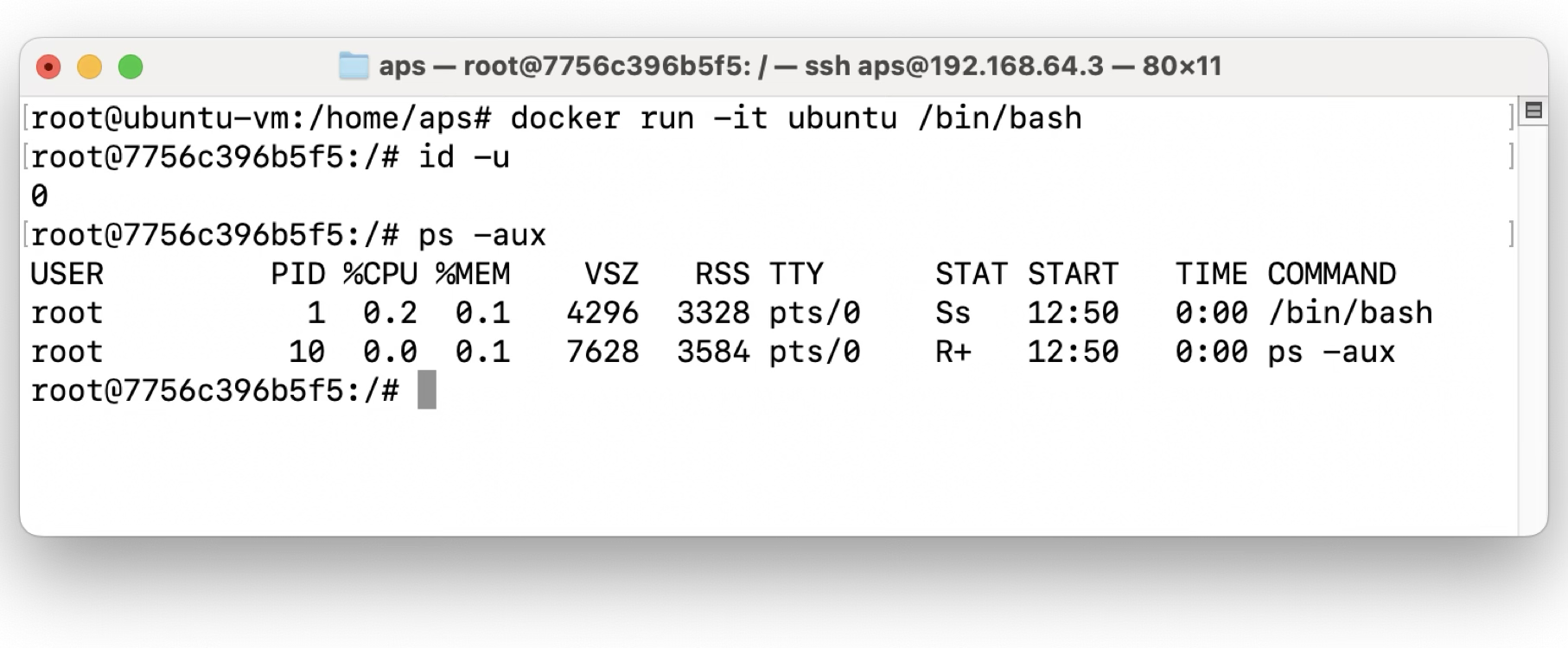
In the meantime we also see our running container as a process on the host system!
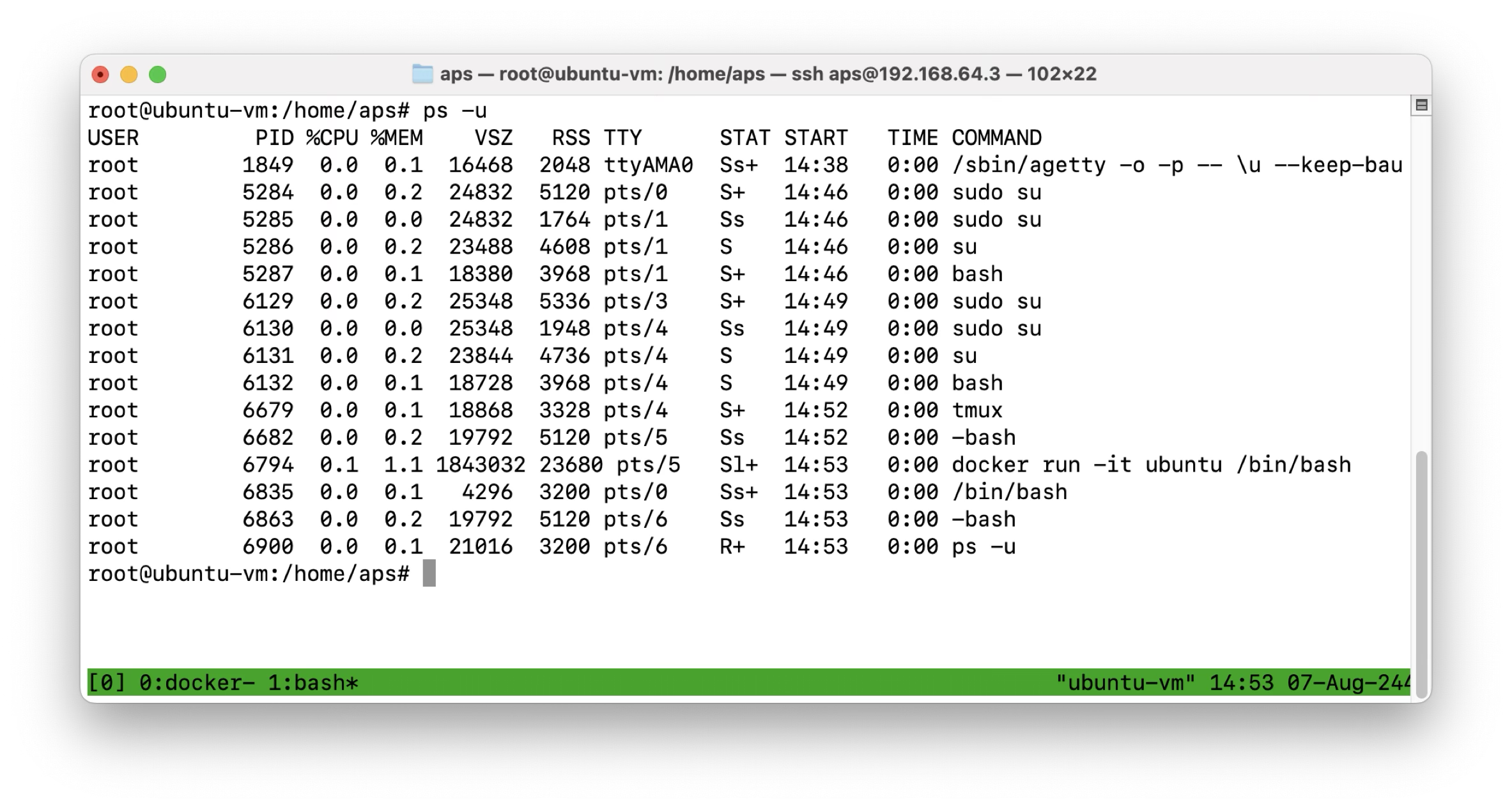
And with that let's have a look on the Kernel features that enables us to isolate a process to a degree where it thinks it is the one and only process of a system.
Kernel Features
The Linux Kernel has a few features that make containers possible. Namely these are:
They will be explained a bit more in detail in the following section. All of them are documented in their corresponding man pages, so you can read more about them there.
Namespaces
Namespaces are a feature of the Linux Kernel that allows you to isolate resources like network, process, and file system. They limit what a container (or process) can see and access. For example, a container can have its own network namespace, so it can have its own IP address and network devices and its own file system with a different Linux distribution than the host. 2
Chroot
Change root (chroot) is a system call that changes the root directory for the current process and its children. This might sound like a not very important feature, but it is crucial for containers. It enables us to tell a process that its root directory is a different directory than the host's root directory. And with that we can create a process that is running with the default file system of a different Linux distribution. 3
Control Groups (cgroups)
Control Groups (cgroups) are a feature of the Linux Kernel that allows you to limit the resources a process can use. This is especially useful to tackle the earlier mentioned noisy neighbor problem. With cgroups you can limit the CPU, memory, and I/O usage of a process, so it doesn't starve other processes on the same system. 4
What is Docker then?
Docker is a tool (and there exist multiple!) that makes it easy to build, run, and manage containers. It uses all the above-mentioned capabilities of the Linux Kernel to isolate processes and wraps them in a nice and easy to use interface. In the following we will write some code to imitate the docker run command. We want to start a "container" that thinks it is the only process on the system and despite running it on an Ubuntu machine, it should think it is running the Debian distribution.
Writing our own Container CLI Tool
With the basic knowledge about the capabilities the Kernel provides let's try to implement some of it.
Attention: The following code only runs a Linux system as we rely on the earlier mentioned Kernel features for process isolation.
func run() {
fmt.Printf("Running %v as process %d\n", os.Args[2:], os.Getpid())
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS,
Unshareflags: syscall.CLONE_NEWNS,
}
err := cmd.Run()
if err != nil {
panic(err)
}
}Before running the command we have to add some attributes. These attributes are exactly the features we talked about earlier. They tell the Kernel how to spawn this process and how to isolate it.
NEWUTS means Unix Timesharing System we need it to get an own hostname for our isolated process. After settings this attribute we are able to change the hostname inside the process without interfering with the host system. NewPID gives the process a new PID starting from 0. If the process forks a new child the child would get the PID 1 and so on.
So with this we have a somewhat isolated process.
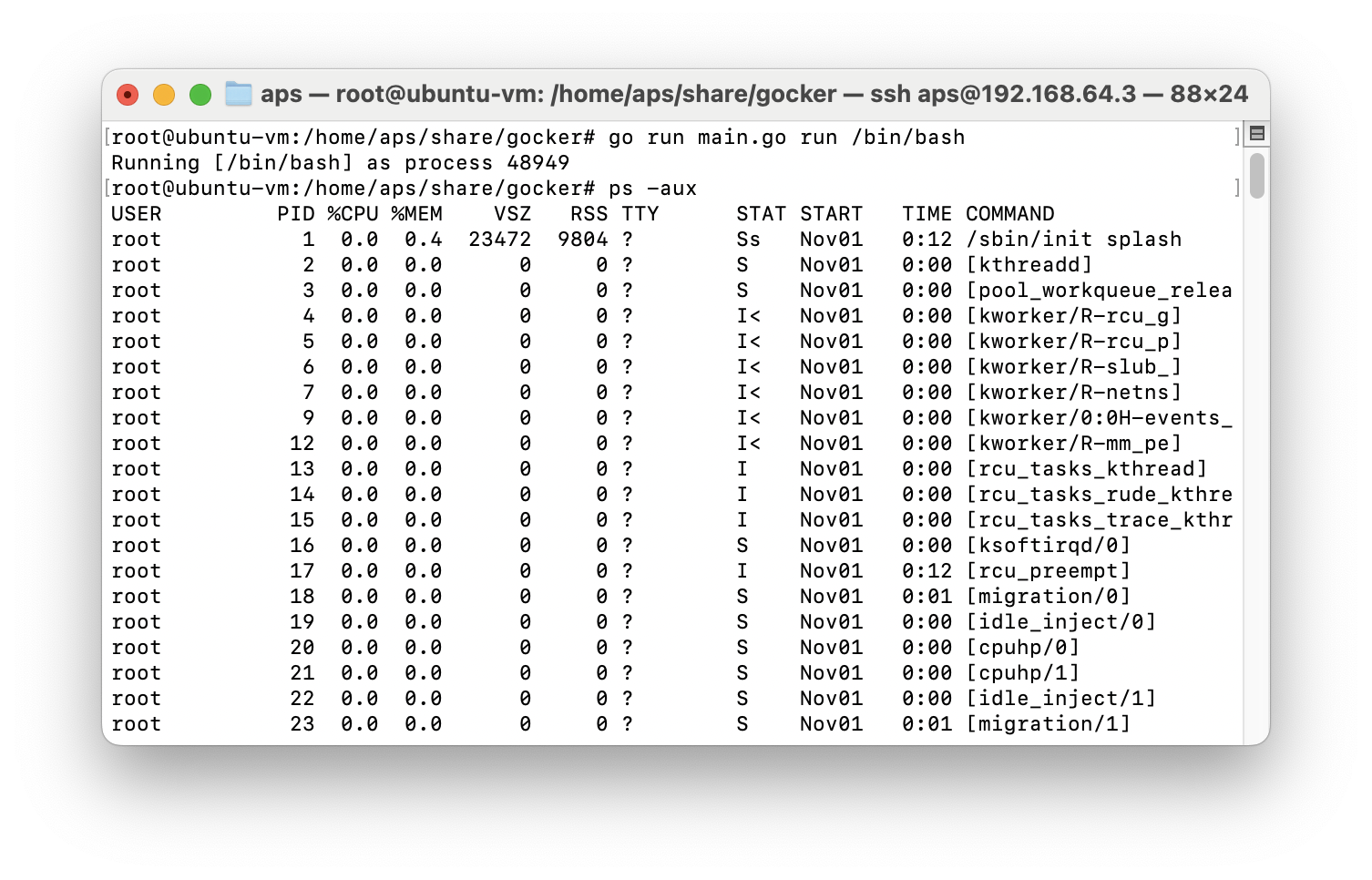
But wait! This process still sees all the other processes on the system and isn't running as PID 0 or 1. For this we need to fork our own process to get our process running with PID 1. Luckily the Kernel or more specific the virtual file system /proc offers a convenient way to do this. We can just call /proc/self/exec to fork ourselves and apply all the discussed isolation features.
func run() {
fmt.Printf("Running %v as process %d\n", os.Args[2:], os.Getpid())
cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...)
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS,
Unshareflags: syscall.CLONE_NEWNS,
}
err := cmd.Run()
if err != nil {
panic(err)
}
}
func child() {
fmt.Printf("Running %v as process %d\n", os.Args[2:], os.Getpid())
syscall.Sethostname([]byte("container"))
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
err := cmd.Run()
if err != nil {
panic(err)
}
}We fork ourselves and additionally use the Sethostname syscall to directly change the hostname of our process. The result looks like this:
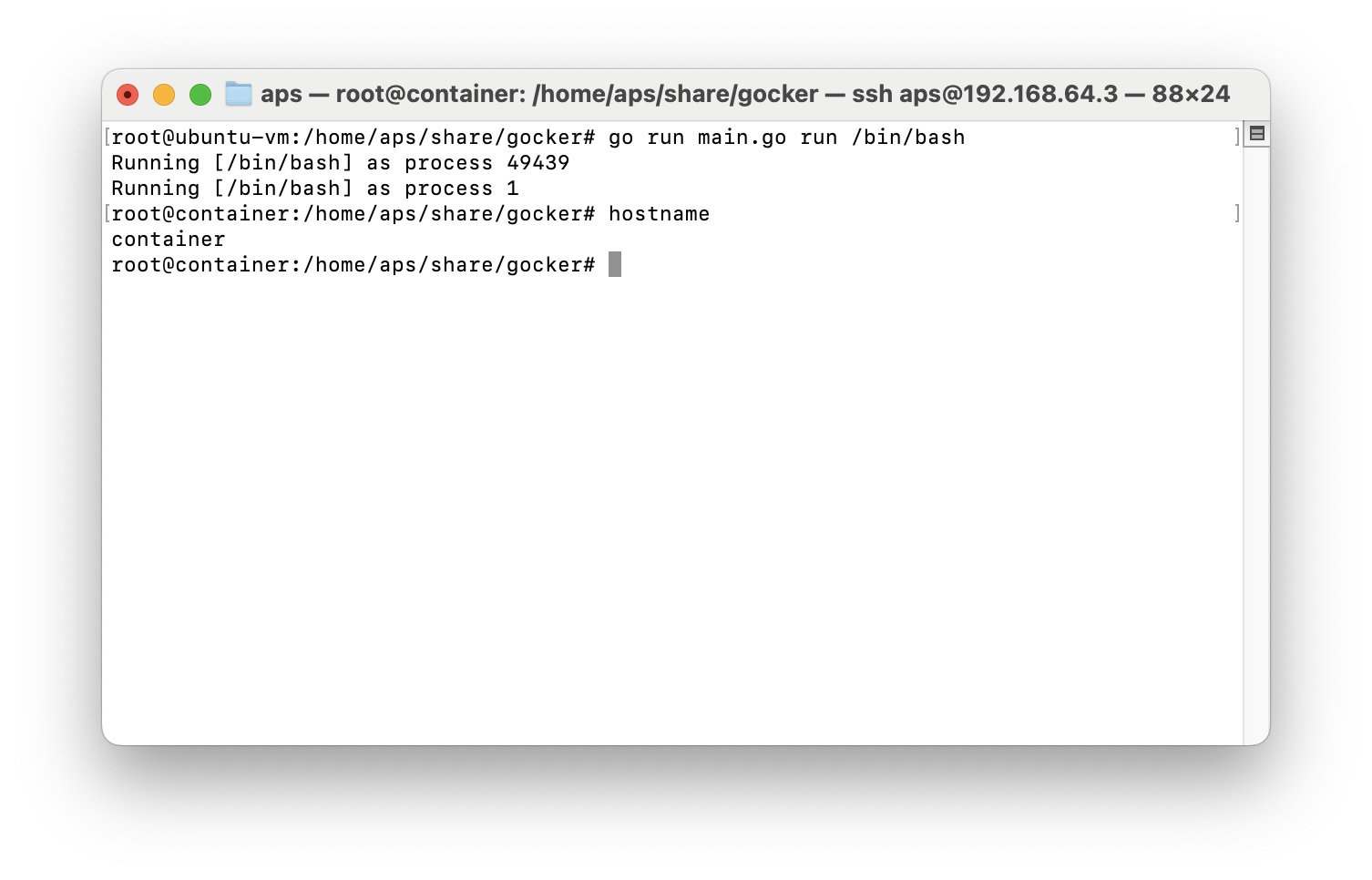
Please note that we now see the Running [/bin/bash] as ... two times. The reason for this is the fork of the parent process to be able to call syscall.Sethostname([]byte("container")) for our child process.
Unexpectedly, this process still sees all the other processes running on the system. The reason for this is the /proc virtual file system. It exposes all the runtime metrics the Kernel knows about the system, and we just mounted the host file system into our isolated process. But we already have a way to fix this. Instead of only setting the hostname of our container we can additionally get our own /proc file system.
func child() {
fmt.Printf("Running %v as process %d\n", os.Args[2:], os.Getpid())
syscall.Sethostname([]byte("container"))
syscall.Mount("proc", "proc", "proc", 0, "")
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
err := cmd.Run()
if err != nil {
panic(err)
}
}Finally, we want to provide our process its own file system. And once we are already on it let's use the official docker image of Debian to transform our process into a process running on a Debian Linux. The image of a running container can easily extracted like this:
docker run -it debian sh
# install ps and other tools
apt update && apt install procps
docker export container_name > output.tar
mkdir debianfs && cd debianfs
mv debian.tar debianfs
tar xvf debian.tarAnd with that we have the full file system with all default configurations of a Debian Linux. Now we just have to attach it to our process using chroot.
func child() {
fmt.Printf("Running %v as process %d\n", os.Args[2:], os.Getpid())
syscall.Sethostname([]byte("container"))
syscall.Chroot("/home/aps/share/gocker/debianfs")
syscall.Chdir("/")
syscall.Mount("proc", "proc", "proc", 0, "")
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
err := cmd.Run()
if err != nil {
panic(err)
}
}This is the output of ps and the os-release of our process after applying all the changes:
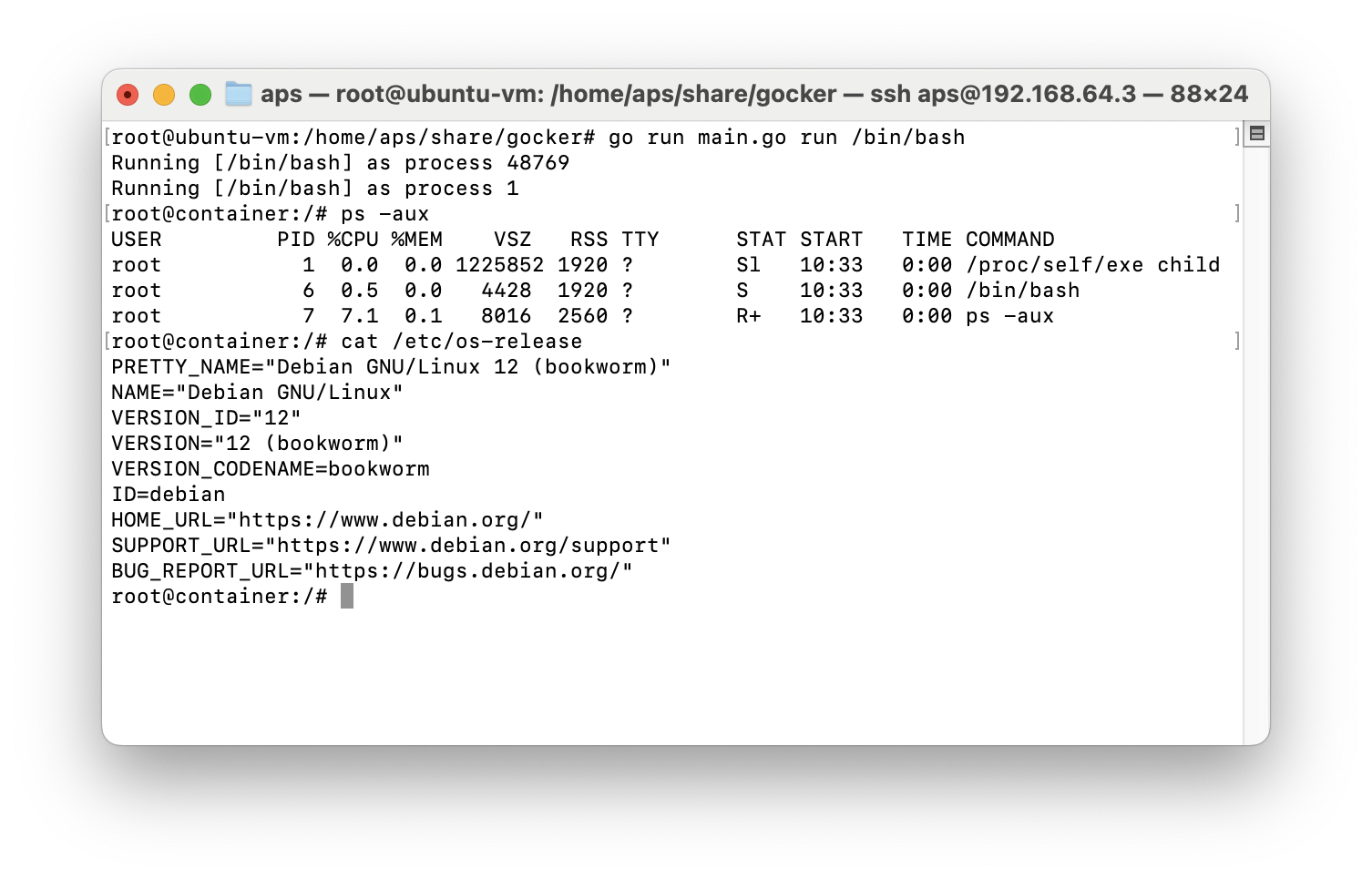
We know have a process that is isolated from the host system. The process doesn't see any processes from the host and even has its own file system based on Debian. Obviously there are many more features of namespaces we have not used, like isolating the network for our process. But I hope these are enough insights to get the core idea of containers on Linux.
The missing part are control groups (cgroups), but I will maybe cover them in a future post. But if you know Kubernetes: cgroups enable the limits on a pod.
Conclusion
Containers are no black magic. They use resources provided by the Linux Kernel to isolate process and manipulate their root directory. We needed about 75 lines of code (with comments) to implement the basic features to emulate the docker run command. The code is based on the excellent talk and code of Liz Rice some years ago, so if you want to get a more interactive version of this post check the talk!
As always the full code can be found on GitHub.